
Opened 10 years ago
Closed 10 years ago
#93 closed Support (fixed)
problem when running in OpenMP mode
| Reported by: | bszintai | Owned by: | jbrioude |
|---|---|---|---|
| Priority: | major | Milestone: | |
| Component: | FP other | Version: | FLEXPART-WRF |
| Keywords: | Cc: | rstow |
Description
Hello,
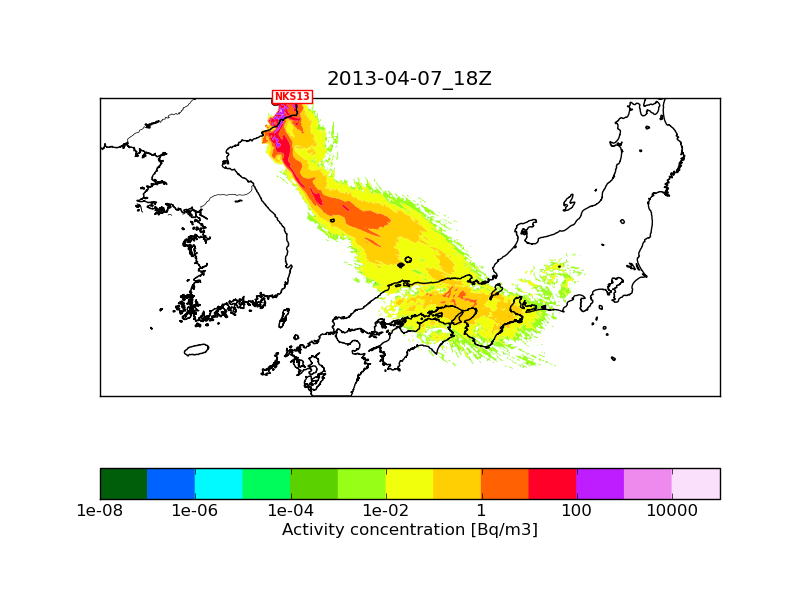
I am running Flexpart-WRF 3.1 for nested input and output domains with 10 million particles. I get significantly different tracer clouds when I run in serial (1 cpu) or in OpenMP mode (4 or 6 OpenMP threads). For the OpenMP run it seems as if the tracer cloud would have much less particles (resembles a run with 2-3 million particles) then in the serial run (see attached plots). There is no difference between the 4 and 6 thread OpenMP runs and I get the same problem with gnu and intel compilers.
When I do not use input and output nesting, then there seems to be no such problem (i.e. serial and OpenMP runs are rather similar).
Thanks a lot for your help in advance.
Balazs
Attachments (17)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (36)
comment:1 Changed 10 years ago by DefaultCC Plugin
- Cc rstow added
Changed 10 years ago by bszintai
comment:2 Changed 10 years ago by jbrioude
- Owner changed from somebody to jbrioude
- Status changed from new to accepted
Hi Balazs,
Can you send your flexpart-wrf input file?
Thanks
comment:3 Changed 10 years ago by bszintai
Hi,
Thanks for your quick answer, I have added the input file.
Balazs
Changed 10 years ago by jbrioude
Changed 10 years ago by jbrioude
Changed 10 years ago by jbrioude
comment:4 Changed 10 years ago by jbrioude
Hi,
Can you try coordtrafo.f90, conccalc_reg.f90 and conccalc_irreg.f90 and see if it fixes your problem?
if not, can you try with LAGESPECTRA=1 ?
When you run FLEXPART-WRF, it gives some output messages. The lines that say "SECONDS SIMULATED" give the number of trajectories calculated at every time of output. Is this number different when you use the serial and open-mp version?
Thanks
comment:5 Changed 10 years ago by pesei
Jerome, just a guess without having looked into the code: could it have to do with initialisation of random numbers (possibly being the same for each thread)?
comment:6 Changed 10 years ago by bszintai
Hello,
Thanks for the answer.
I have tried with the new routines but it gives the same result. Also LAGESPECTRA=1 gives the same result. In the output message of the model the number of trajectories are the same for serial and openmp runs.
Balazs
comment:7 Changed 10 years ago by jbrioude
Okay.
When you say "When I do not use input and output nesting, then there seems to be no such problem", can you be more specific?
is it when the input nesting is not here or is it when the flexpart output nesting is not here?
Jerome
comment:8 Changed 10 years ago by bszintai
Hi Jerome,
I have now rerun this experiment with 10 million particles (including your fix of 3 routines) with all the possible combinations of input/output nesting and the result is that the OpenMP problem (the different cloud from the serial run) is there regardless of input/output nesting choice.
Sorry for that. My original statement about this was based on a previous case with much fewer particles and it could also be that I have made a mistake there.
So now I can state that this OpenMP problem is not dependent on the nesting choice, it is always there.
Thanks,
Balazs
comment:9 Changed 10 years ago by jbrioude
Thanks.
To avoid the problem that pesei pointed out, can you restrict the number of particles to 1 million?
I have an other test for you: can you try the OpenMP version with 1 core and see if it's different than the serial version?
Thanks
comment:10 Changed 10 years ago by bszintai
Hello,
I have made the three new runs:
- serial
- OpenMP with 1 core (omp1)
- OpenMP with 6 cores (omp6)
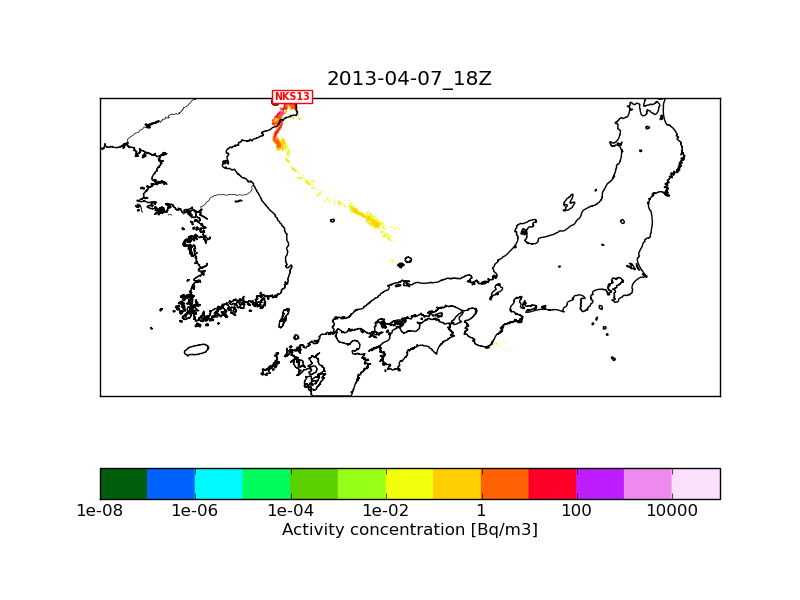
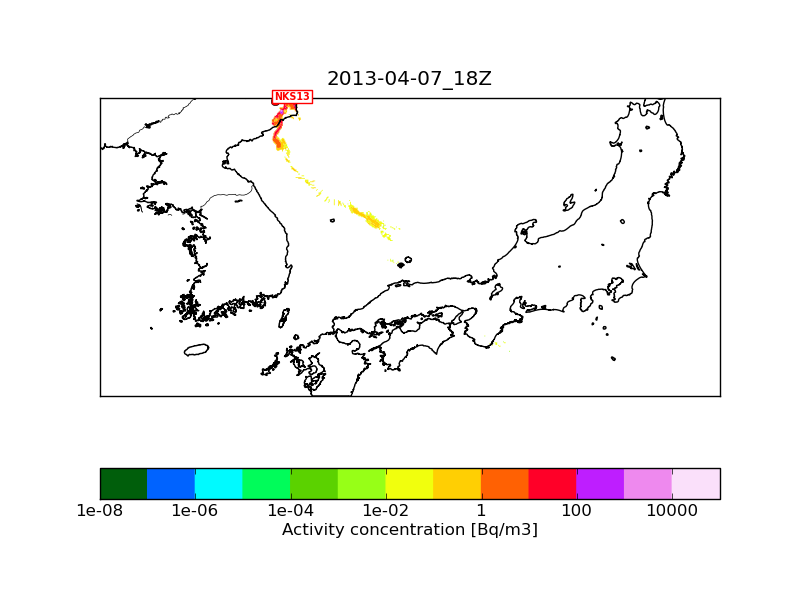
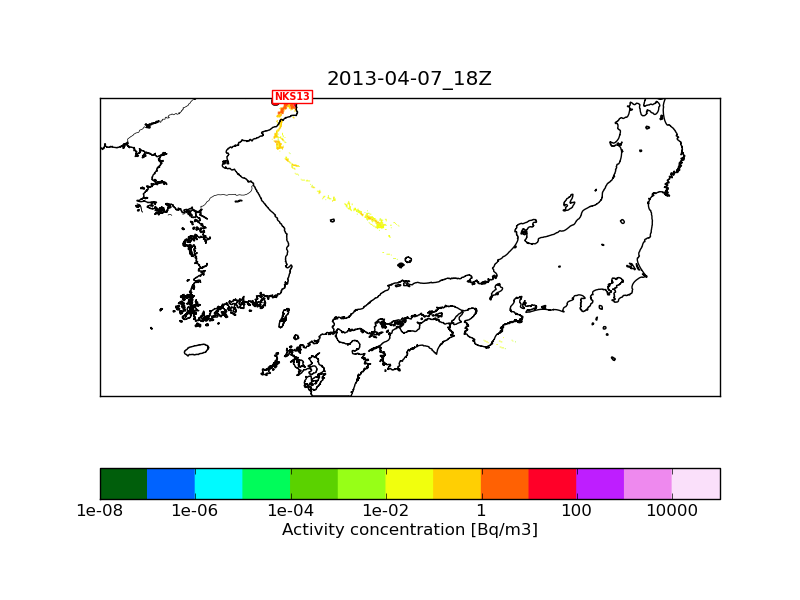
It is a bit difficult to judge due to the small number of particles but I think that "serial" and "omp1" are the same while "omp6" has the problem of seemingly less particles (especially close to the source).
comment:11 follow-up: ↓ 12 Changed 10 years ago by bszintai
I have attached the plots for the three runs.
Balazs
comment:12 in reply to: ↑ 11 ; follow-up: ↓ 14 Changed 10 years ago by pesei
OK, it seems also that the concentration is too low. Then it is not a problem of identical particle paths but rather a wrong particle number being used in concentration calculation or similar. Can you please evaluate the ratio of the 1c to the 6c run concentrations. If it is not a constant, could you please make a scatter plot of the two data sets?
btw, it would be appreciated if you add yourself in FpUsers, if you haven't done so yet.
comment:13 follow-up: ↓ 15 Changed 10 years ago by jbrioude
I have a comment:
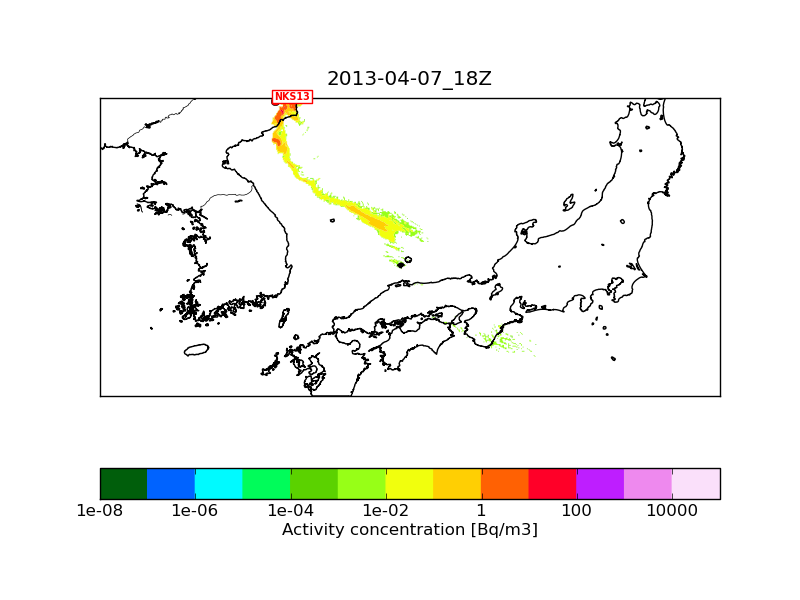
The differences between NKS13_2013-04-07_18.png and NKS13_2013-04-07_18_1M_serial.png shouldn't be the consequence of using 1 million of particles instead of 10 millions.
Did you change something in the namelist beside the number of trajectories?
just to make sure: did you compile in openmp after doing: make -f makefile.mom clean?
Thanks
comment:14 in reply to: ↑ 12 Changed 10 years ago by bszintai
Replying to pesei:
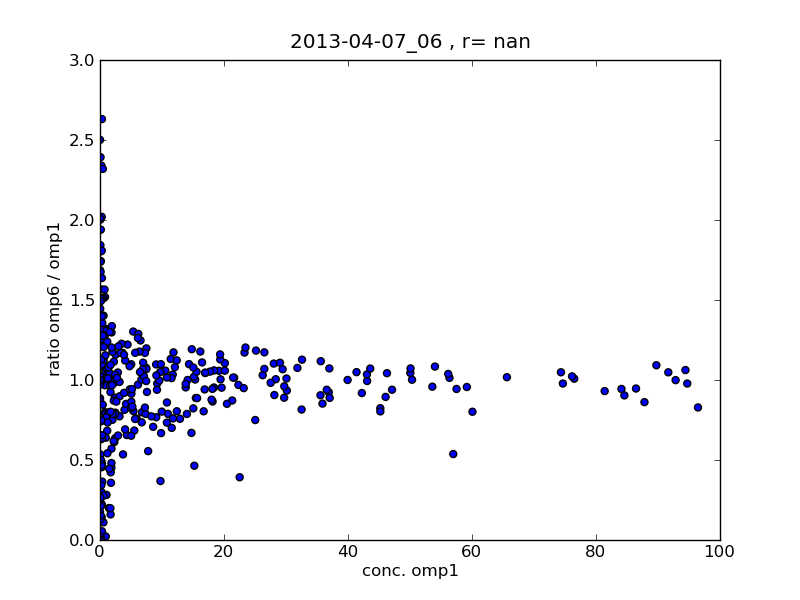
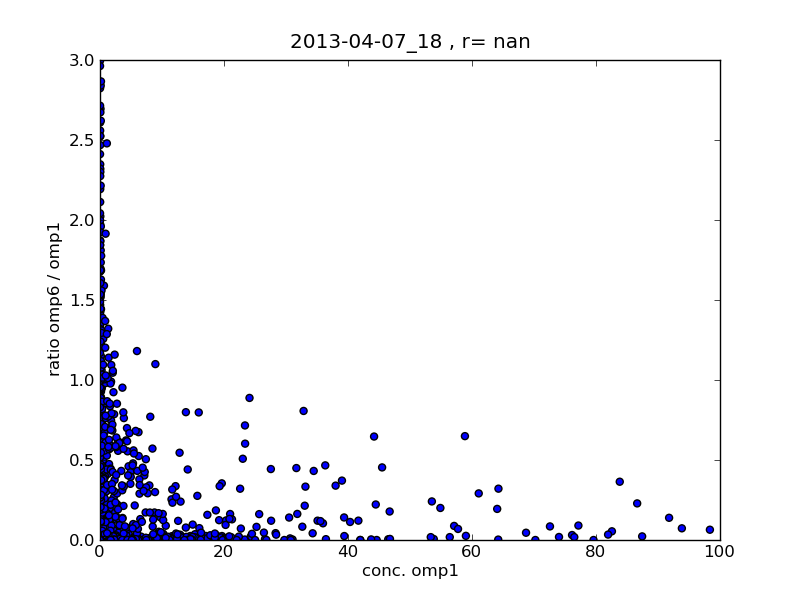
The ratio of the concentrations in the 1 core OpenMP (omp1) and the 6 core OpenMP (omp6) runs is not constant. I attach three scatter plots. The first two show the ratio of omp6/omp1 as a function of the omp1 concentration at two simulation times (+3h and +15h of simulation). At the beginning of the simulation (+3h) there are a lot of grid points where the ratio is close to 1.0, especially for higher concentrations. If we go further in the simulation (+15h) the ratio decreases.
I also attach a third scatter plot which demonstrates that the serial and the omp1 run is the same and the scatter plot calculation works correctly.
Thanks,
Balazs
comment:15 in reply to: ↑ 13 Changed 10 years ago by bszintai
Replying to jbrioude:
I have a comment:
The differences between NKS13_2013-04-07_18.png and NKS13_2013-04-07_18_1M_serial.png shouldn't be the consequence of using 1 million of particles instead of 10 millions.
Did you change something in the namelist beside the number of trajectories?
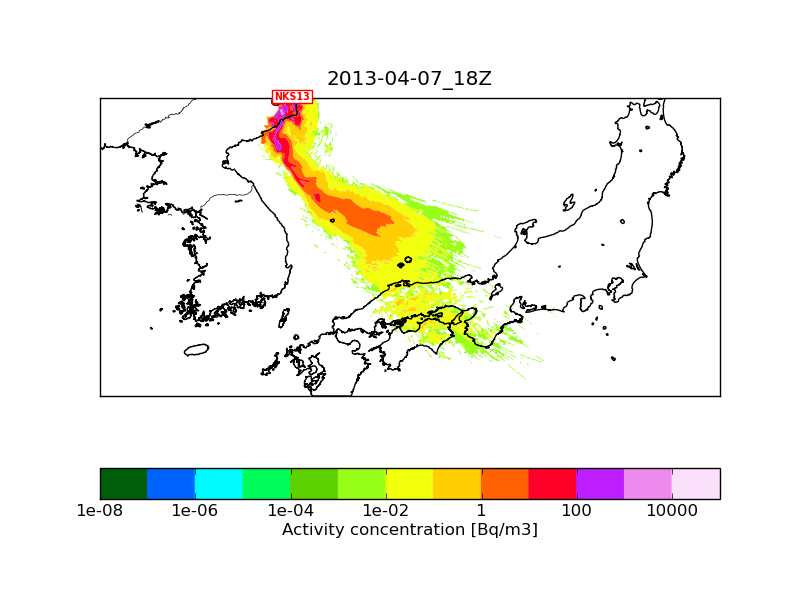
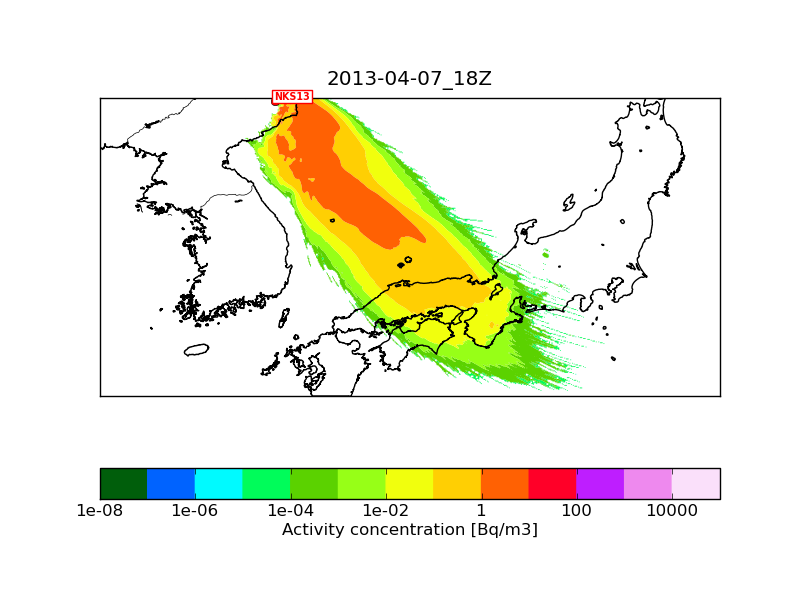
The only difference is that "NKS13_2013-04-07_18.png" used an inner meteorological nest of 1 km resolution next to the mother nest of 3 km, while "NKS13_2013-04-07_18_1M_serial.png" used the mother nest only (otherwise the namelists and the met fields used are identical). I attach a plot with 10 million particles where only the 3 km mother nest was used. This should be comparable with "NKS13_2013-04-07_18_1M_serial.png". I think the reason why the 1M run has so few particles is that here I plot level_1 which is at 100 m height above ground level, and due to topography quite few particles get so close to the surface. If I plot level_2 (between 100m and 3500 m) then the 1M and the 10M runs are more similar (I also attach these two plots).
just to make sure: did you compile in openmp after doing: make -f makefile.mom clean?
Thanks
Yes, I have made the cleaning before compiling the openmp version.
Thanks,
Balazs
comment:16 follow-up: ↓ 17 Changed 10 years ago by jbrioude
Hi,
If the differences between NKS13_2013-04-07_18_1M_serial_lev2.png and NKS13_2013-04-07_18_10M_serial_lev2.png is using 1 million and 10 million trajectories, then I understand the difference between NKS13_2013-04-07_18.png and NKS13_2013-04-07_18_omp6.png
Can you try to use newrandomgen=1 in par_mod.f90 (line 250) and see if it fixes your problem?
Thanks
comment:17 in reply to: ↑ 16 Changed 10 years ago by bszintai
Hi Jerome,
Thanks for your help, setting newrandomgen=1 fixes the problem, so now serial and OpenMP runs are identical. I have tested both with 1 M and 10 M particles. I attach the serial and omp6 run with 10 M particles. In the case of the serial run, there is a huge difference between the newrandomgen=0 and newrandomgen=1 version. Could you comment on that?
Thanks a lot,
Balazs
comment:18 Changed 10 years ago by jbrioude
Is the differences you mentioned between
NKS13_2013-04-07_18.png
and
NKS13_2013-04-07_18_serial_10M_lev1_newrand.png ?
It might come from differences in vertical transport due to differences in the gaussian distribution of the random number generator. As mentioned in the model description (cf Brioude et al., 2013 in GMD), newrandomgen=1 uses a more precise random number generator than newrandomgen=0 but uses a little bit more CPU time.
I didn't find such differences, but I will investigate it in more details.
In the meantime, I advise you to use newrandomgen=1.
comment:19 Changed 10 years ago by jbrioude
- Resolution set to fixed
- Status changed from accepted to closed
serial run