Usage¶
flex_extract is a command-line tool. In the first versions, it was started via a korn shell script and since version 6, the entry point was a python script. From version 7.1, a bash shell script was implemented to call flex_extract with the command-line parameters.
To submit an extraction job, change the working directory to the subdirectory Run (directly under the flex_extract_vX.X root directory, where X.X is the version number):
cd <path-to-flex_extract_vX.X>/Run
Within this directory you can find everything you need to modify and run flex_extract. The following tree shows a shortened list of directories and important files. The * serves as a wildcard. The brackets [] indicate that the file is present only in certain modes of application.
Run
├── Control
│ ├── CONTROL_*
├── Jobscripts
│ ├── compilejob.ksh
│ ├── job.ksh
│ ├── [joboper.ksh]
├── Workspace
│ ├── CERA_example
│ │ ├── CE000908*
├── [ECMWF_ENV]
├── run_local.sh
└── run.sh
The Jobscripts directory is used to store the Korn shell job scripts generated by a flex_extract run in the Remote or Gateway mode. They are used to submit the setup information to the ECMWF server and start the jobs in ECMWF’s batch mode. The typical user must not touch these files. They are generated from template files which are stored in the Templates directory under flex_extract_vX.X. Usually there will be a compilejob.ksh and a job.ksh script which are explained in the section Control & input data. In the rare case of operational data extraction there will be a joboper.ksh which reads time information from environment variables at the ECMWF servers.
The Controls directory contains a number of sample CONTROL files. They cover the current range of possible kinds of extractions. Some parameters in the CONTROL files can be adapted and some others should not be changed. In this Usage guide we explain how an extraction with flex_extract can be started in the different Application modes and point out some specifics of each dataset and CONTROL file.
Directly under Run you find the files run.sh and run_local.sh and according to your selected Application modes there might also be a file named ECMWF_ENV for the user credentials to quickly and automatically access ECMWF servers.
From version 7.1 on, the run.sh (or run_local.sh) script is the main entry point to flex_extract.
Note
Note that for experienced users (or users of older versions), it is still possible to start flex_extract directly via the submit.py script in directory flex_extract_vX.X/Source/Python.
Job preparation¶
To actually start a job with flex_extract it is sufficient to start either run.sh or run_local.sh. Data sets and access modes are selected in CONTROL files and within the user section of the run scripts. One should select one of the sample CONTROL files. The following sections describes the differences in the application modes and where the results will be stored.
Remote and gateway modes¶
For member-state users it is recommended to use the remote or gateway mode, especially for more demanding tasks, which retrieve and convert the data on ECMWF machines; only the final output files are transferrred to the local host.
- Remote mode
The only difference between both modes is the users working location. In the remote mode you have to login to the ECMWF server and then go to the
Rundirectory as shown above. At ECMWF serversflex_extractis installed in the$HOMEdirectory. However, to be able to start the program you have to load thePython3environment with the module system first.# Remote mode ssh -X <ecuid>@ecaccess.ecmwf.int# On ECMWF server [<ecuid>@ecgb11 ~]$ cd flex_extract_vX.X/Run
- Gateway mode
For the gateway mode you have to log in on the gateway server and go to the
Rundirectory offlex_extract:# Gateway mode ssh <user>@<gatewayserver> cd <path-to-flex_extract_vX.X>/Run
From here on the working process is the same for both modes.
For your first submission you should use one of the example CONTROL files stored in the Control directory. We recommend to extract CERA-20C data since they usually guarantee quick results and are best for testing reasons.
Therefore open the run.sh file and modify the parameter block marked in the file as shown below:
# -----------------------------------------------------------------
# AVAILABLE COMMANDLINE ARGUMENTS TO SET
#
# THE USER HAS TO SPECIFY THESE PARAMETERS:
QUEUE='ecgate'
START_DATE=None
END_DATE=None
DATE_CHUNK=None
JOB_CHUNK=3
BASETIME=None
STEP=None
LEVELIST=None
AREA=None
INPUTDIR=None
OUTPUTDIR=None
PP_ID=None
JOB_TEMPLATE='jobscript.template'
CONTROLFILE='CONTROL_CERA'
DEBUG=0
REQUEST=2
PUBLIC=0
This would retrieve a one day (08.09.2000) CERA-20C dataset with 3 hourly temporal resolution and a small 1° domain over Europe. Since the ectrans parameter is set to 1 the resulting output files will be transferred to the local gateway into the path stored in the destination (SEE INSTRUCTIONS FROM INSTALLATION). The parameters listed in the run.sh file would overwrite existing settings in the CONTROL file.
To start the retrieval you only have to start the script by:
./run.sh
Flex_extract will print some information about the job. If there is no error in the submission to the ECMWF server you will see something like this:
---- On-demand mode! ----
The job id is: 10627807
You should get an email per job with subject flex.hostname.pid
FLEX_EXTRACT JOB SCRIPT IS SUBMITED!
Once submitted you can check the progress of the submitted job using ecaccess-job-list. You should get an email after the job is finished with a detailed protocol of what was done.
In case the job fails you will receive an email with the subject ERROR! and the job name. You can then check for information in the email or you can check on ECMWF server in the $SCRATCH directory for debugging information.
cd $SCRATCH
ls -rthl
The last command lists the most recent logs and temporary retrieval directories (usually extractXXXXX, where XXXXX is the process id). Under extractXXXXX a copy of the CONTROL file is stored under the name CONTROL, the protocol is stored in the file prot and the temporary files as well as the resulting files are stored in a directory work. The original name of the CONTROL file is stored in this new file under parameter controlfile.
flex_extract output directory on ECMWF servers.ӦextractXXXXX
├── CONTROL
├── prot
├── work
│ ├── temporary files
│ ├── CE000908* (resulting files)
If the job was submitted to the HPC ( queue=cca or queue=ccb ) you may login to the HPC and look into the directory /scratch/ms/ECGID/ECUID/.ecaccess_do_not_remove for job logs. The working directories are deleted after job failure and thus normally cannot be accessed.
To check if the resulting files are still transferred to local gateway server you can use the command ecaccess-ectrans-list or check the destination path for resulting files on your local gateway server.
Local mode¶
To get to know the working process and to start your first submission you could use one of the example CONTROL files stored in the Control directory as they are. For quick results and for testing reasons it is recommended to extract CERA-20C data.
Open the run_local.sh file and modify the parameter block marked in the file as shown below. The differences are highlighted.
Take this for member-state user |
Take this for public user |
# -----------------------------------------
# AVAILABLE COMMANDLINE ARGUMENTS TO SET
#
# THE USER HAS TO SPECIFY THESE PARAMETERs:
#
QUEUE=''
START_DATE=None
END_DATE=None
DATE_CHUNK=None
JOB_CHUNK=None
BASETIME=None
STEP=None
LEVELIST=None
AREA=None
INPUTDIR='./Workspace/CERA'
OUTPUTDIR=None
PP_ID=None
JOB_TEMPLATE=''
CONTROLFILE='CONTROL_CERA'
DEBUG=0
REQUEST=0
PUBLIC=0
|
# -----------------------------------------
# AVAILABLE COMMANDLINE ARGUMENTS TO SET
#
# THE USER HAS TO SPECIFY THESE PARAMETERs:
#
QUEUE=''
START_DATE=None
END_DATE=None
DATE_CHUNK=None
JOB_CHUNK=None
BASETIME=None
STEP=None
LEVELIST=None
AREA=None
INPUTDIR='./Workspace/CERApublic'
OUTPUTDIR=None
PP_ID=None
JOB_TEMPLATE=''
CONTROLFILE='CONTROL_CERA.public'
DEBUG=0
REQUEST=0
PUBLIC=1
|
This would retrieve a one day (08.09.2000) CERA-20C dataset with 3 hourly temporal resolution and a small 1° domain over Europe. The destination location for this retrieval will be within the Workspace directory within Run. This can be changed to whatever path you like. The parameters listed in run_local.sh would overwrite existing settings in the CONTROL file.
To start the retrieval you then start the script by:
./run_local.sh
While job submission on the local host is convenient and easy to monitor (on standard output), there are a few caveats with this option:
There is a maximum size of 20GB for single retrieval via ECMWF Web API. Normally this is not a problem but for global fields with T1279 resolution and hourly time steps the limit may already apply.
If the retrieved MARS files are large but the resulting files are relative small (small local domain) then the retrieval to the local host may be inefficient since all data must be transferred via the Internet. This scenario applies most notably if
etadothas to be calculated via the continuity equation as this requires global fields even if the domain is local. In this case job submission via ecgate might be a better choice. It really depends on the use patterns and also on the internet connection speed.
Selection and adjustment of CONTROL files¶
This section describes how to work with the CONTROL files. A detailed explanation of CONTROL file parameters and naming compositions can be found here. The more accurately the CONTROL file describes the retrieval needed, the fewer command-line parameters are needed to be set in the run scripts. With version 7.1 all CONTROL file parameters have default values. They can be found in section CONTROL parameters or in the CONTROL.documentation file within the Control directory. Only those parameters which need to be changed for a dataset retrieval needs to be set in a CONTROL file!
The limitation of a dataset to be retrieved should be done very cautiously. The datasets can differ in many ways and vary over the time in resolution and parameterisations methods, especially the operational model cycles improves through a lot of changes over the time. If you are not familiar with the data it might be useful or necessary to check for availability of data in ECMWF’s MARS:
Public users can use a web mask to check on data or list available data at this Public datasets web interface.
Member state users can check availability of data online in the MARS catalogue.
There you can select step by step what data suits your needs. This would be the most straightforeward way of checking for available data and therefore limit the possibility of flex_extract to fail. The following figure gives an example how the web interface would look like:
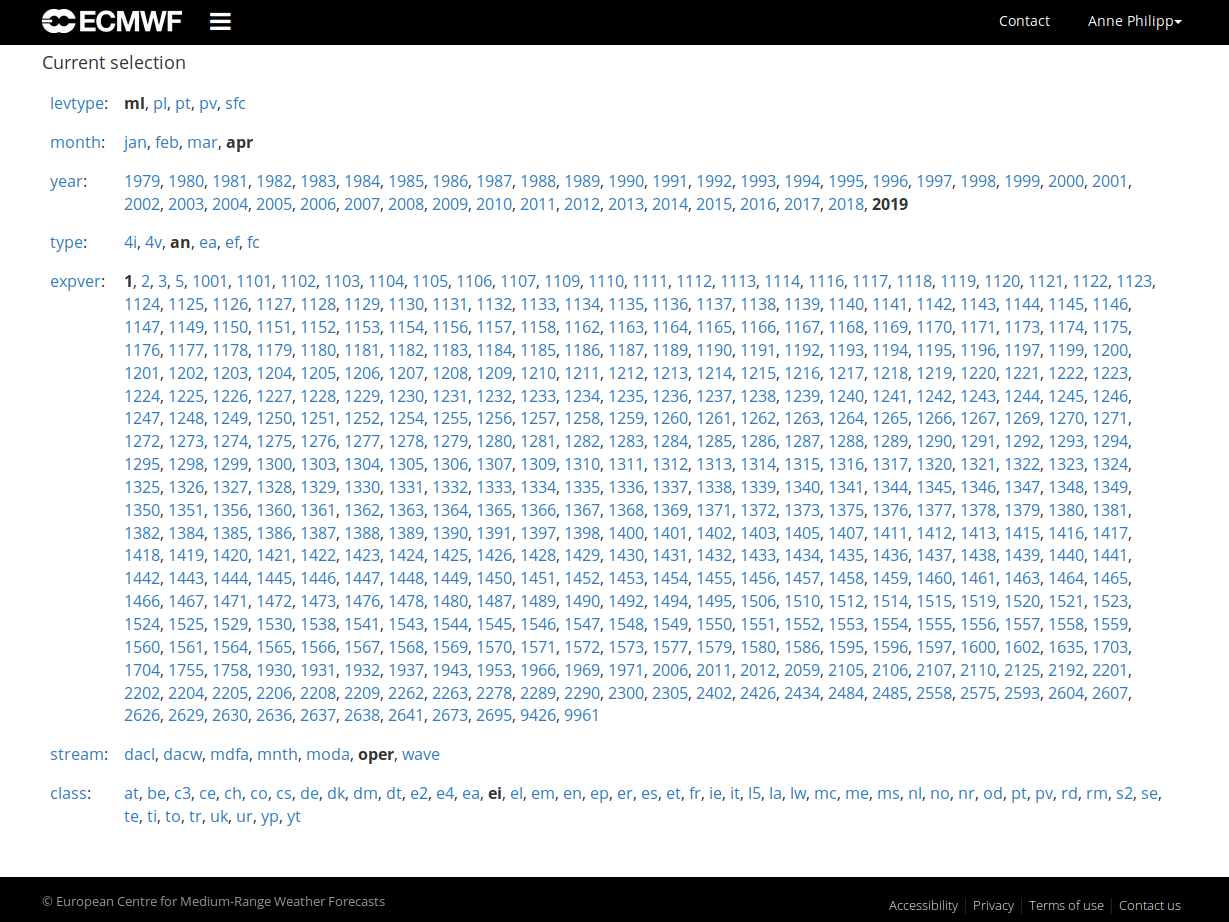
Additionally, you can find a lot of helpful links to dataset documentations, direct links to specific dataset web catalogues or further general information at the link collection in the ECMWF data section.
Flex_extract is specialised to retrieve a limited number of datasets, namely ERA-Interim, CERA-20C, ERA5 and HRES (operational data) as well as the ENS (operational data, 15-day forecast). The limitation relates mainly to the dataset itself, the stream (what kind of forecast or what subset of dataset) and the experiment number. Mostly, the experiment number is equal to 1 to signal that the actual version should be used.
The next level of differentiation would be the field type, level type and time period. Flex_extract currently only supports the main streams for the re-analysis datasets and provides extraction of different streams for the operational dataset. The possibilities of compositions of dataset and stream selection are represented by the current list of example CONTROL files. You can see this in the naming of the example files:
CONTROL files distributed with flex_extract. ҦCONTROL_CERA
CONTROL_CERA.global
CONTROL_CERA.public
CONTROL_EA5
CONTROL_EA5.global
CONTROL_EI
CONTROL_EI.global
CONTROL_EI.public
CONTROL_OD.ELDA.FC.eta.ens.double
CONTROL_OD.ENFO.CF
CONTROL_OD.ENFO.CV
CONTROL_OD.ENFO.PF
CONTROL_OD.ENFO.PF.36hours
CONTROL_OD.ENFO.PF.ens
CONTROL_OD.OPER.4V.operational
CONTROL_OD.OPER.FC.36hours
CONTROL_OD.OPER.FC.eta.global
CONTROL_OD.OPER.FC.eta.highres
CONTROL_OD.OPER.FC.gauss.highres
CONTROL_OD.OPER.FC.operational
CONTROL_OD.OPER.FC.twicedaily.1hourly
CONTROL_OD.OPER.FC.twicedaily.3hourly
The main differences and features in the datasets are listed in the table shown below:
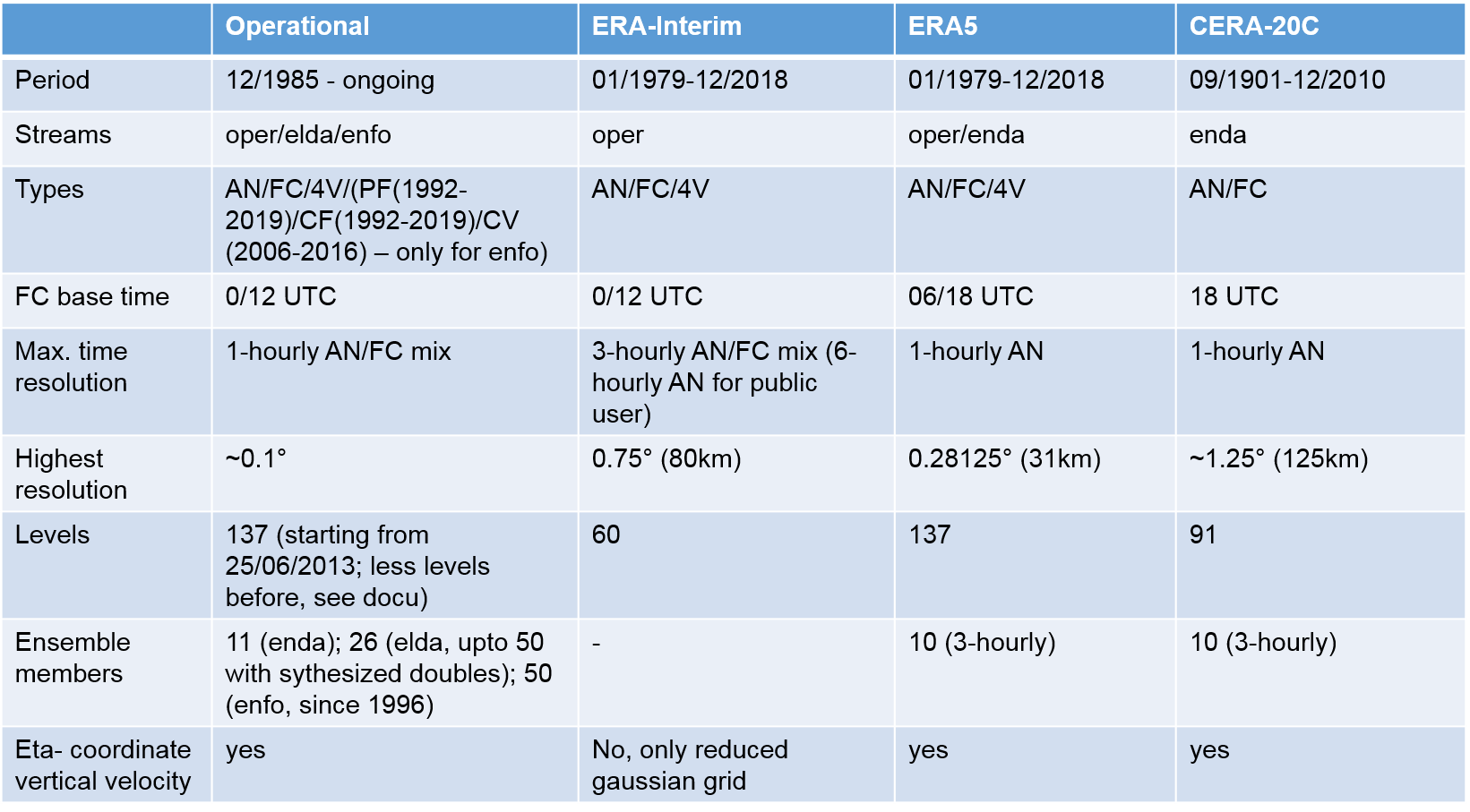
A common problem for beginners in retrieving ECMWF datasets is a mismatch in the choice of values for these parameters. For example, if you try to retrieve operational data for 24 June 2013 or earlier and set the maximum level to 137, you will get an error because this number of levels was introduced only on 25 June 2013. Thus, be careful in the combination of space and time resolution as well as the field types.
Note
Sometimes it might not be clear how specific parameters in the control file must be set in terms of format. Please consult the description of the parameters in section CONTROL parameters or have a look at the ECMWF user documentation for MARS keywords
In the following, we shortly discuss the typical retrievals for the different datasets and point to the respective CONTROL files.
Public datasets¶
The main characteristic in the definition of a CONTROL file for a public dataset is the parameter DATASET. Its specification enables the selection of a public dataset in MARS. Without this parameter, the request would not find the dataset.
For the two public datasets CERA-20C and ERA-Interim an example file with the ending .public is provided and can be used straightaway.
CONTROL_CERA.public
CONTROL_EI.public
For CERA-20C it seems that there are no differences compared the full dataset, whereas the public ERA-Interim has only 6-hourly analysis fields, without forecasts to fill in between, for model levels. Therefore, it is only possible to retrieve 6-hourly data for public ERA-Interim.
Note
In principle, ERA5 is a public dataset. However, since the model levels are not yet publicly available, it is not possible to retrieve ERA5 data to drive the FLEXPART model. As soon as this is possible it will be announced at the community website and on the FLEXPART user email list.
CERA¶
For this dataset, it is important to keep in mind that it is available for the period 09/1901 until 12/2010, and that the temporal resolution is limited to 3 h.
It is also a pure ensemble data assimilation dataset and is stored under the enda stream.
There are 10 ensemble members. The example CONTROL files retrieves the first member only (number=0). You may change this to another number or a list of numbers (e.g. NUMBER 0/to/10).
Another important difference to all other datasets is that there is one forecast per day, starting at 18 UTC. The forecast lead time is 24 hours and extends beyond the calendar day. Therefore, flex_extract needs to extract also the day before the first day for which data are desired, which is handled automatically.
ERA 5¶
This is the latest re-analysis dataset, and has a temporal resolution of 1-h (analysis fields). At the time of writing, it is available until April 2019 with regular release of new months.
The original horizontal resolution is 0.28125° which needs some caution in the definition of the domain, since the length of the domain in longitude or latitude direction must be an integer multiple of the resolution. It is also possible to use 0.25 for the resolution; MARS will then automatically interpolate to this resolution which is still close enough to be acceptable.
The forecast starting time is 06/18 UTC which is important for the flux data. Correspondingly, one should set in the CONTROL file ACCTIME 06/18, ACCMAXSTEP 12, and ACCTYPE FC.
Note
ERA5 also includes an ensemble data assimilation system but related fields are not yet retrievable with flex_extract since the deaccumulation of the flux fields works differently in this stream. Ensemble field retrieval for ERA5 is a to-do for the future.
ERA-Interim¶
The production of this re-analysis dataset has stopped on 31 August 2019!
It is available for the period from 1 January 1979 to 31 August 2019. The etadot parameter is not available in this dataset. Therefore, one must use the GAUSS parameter, which retrieves the divergence field in addition and calculates the vertical velocity from the continuity equation in the Fortran program calc_etadot. While the analysis fields are only available for every 6th hour, the dataset can be made 3-hourly by adding forecast fields in between. No ensemble members are available.
Operational data¶
This data set provides the output of the real-time atmospheric model runs in high resolution, including 10-day forecasts. The model undergoes frequent adaptations and improvements. Thus, retrieving data from this dataset requires extra attention in selecting correct settings of the parameters. See [Table of datasets] for the most important parameters.
Currently, fields can be retrieved at 1 h temporal resolution by filling the gaps between analysis fields with 1-hourly forecast fields. Since 4 June 2008, the eta coordinate vertical velocity is directly available from MARS, therefore ETA should be set to 1 to save computation time. The horizontal resolution can be up to 0.1° and in combination with 137 vertical levels can lead to problems in terms of job duration and disk space quota.
It is recommended to submit such high resolution cases as single day retrievals (see JOB_CHUNK parameter in run.sh script) to avoid job failures due to exceeding limits.
CONTROL files for standard retrievals with a mix of analysis and forecast fields are listed below:
CONTROL_OD.OPER.4V.eta.global
CONTROL_OD.OPER.FC.eta.global
CONTROL_OD.OPER.FC.eta.highres
CONTROL_OD.OPER.FC.gauss.highres
These files defines the minimum number of parameters necessary to retrieve a daily subset. The given settings for the TYPE parameter are already optimised, and should only be changed if you know what you are doing. Grid, domain, and temporal resolution may be changed according to availability.
Note
Please see Information about MARS retrievement for hints about retrieval efficiency and troubleshooting.
- Long forecast
It is possible to retrieve long forecasts exceeding one day. The forecast period available depends on the date and forecast field type. Please use MARS catalogue to check the availability. Below are some examples for 36 hour forecasts of Forecast (FC), Control forecast (CF) and Calibration/Validation forecast (CV). The CV field type was only available 3-hourly from 2006 up to 2016. It is recommended to use the CF type since this is available from 1992 (3-hourly) on up to today (1-hourly). CV and CF field types belong to the Ensemble prediction system (ENFO) which currently works with 50 ensemble members. Please be aware that in this case it is necessary to set the type for flux fields explicitly, otherwise a default value might be selected, different from what you expect!
CONTROL_OD.ENFO.CF.36hours CONTROL_OD.ENFO.CV.36hours CONTROL_OD.OPER.FC.36hours
- Half-day retrievals
If a forecast is wanted for half a day only, this can be done by substituting the analysis fields by forecast fields as shown in files with
twicedailyin their name. They produce a full-day retrieval with pure 12 hour forecasts, twice a day. It is also possible to use the operational version which would obtain the time information from ECMWF’s environment variables and therefore use the newest forecast for each day. This version uses aBASETIMEparameter which tells MARS to extract the exact 12 hours up to the selected date. If theCONTROLfile withbasetimein the filename is used, this can be done for any other date, too.CONTROL_OD.OPER.FC.eta.basetime CONTROL_OD.OPER.FC.operational CONTROL_OD.OPER.FC.twicedaily.1hourly CONTROL_OD.OPER.FC.twicedaily.3hourly
- Ensemble members
The retrieval of ensemble members was already mentioned in the pure forecast section and for CERA-20C data. This
flex_extractversion allows to retrieve the Ensemble Long window Data Assimilation (ELDA) stream from the operational dataset. Until May 2019, there were 25 ensemble members and a control run (number 0). Starting with June 2019, the number of ensemble members has been increased to 50. Therefore, we created the option to create 25 additional “pseudo-ensemble members” for periods before June 2019. The original 25 members from MARS are taken, and the difference between the member value and the control value is subtracted twice. This is done if the parameterDOUBLEELDAis included and set it to1.CONTROL_OD.ELDA.FC.eta.ens.double CONTROL_OD.ENFO.PF.ens
Specific features¶
- rrint
Selects the disaggregation scheme for precipitation flux: old (
0) or new (1). See Disaggregation of flux data for explanation.- cwc
If present and set to
1, the total cloud water content will be retrieved in addition. This is the sum of cloud liquid and cloud ice water content.- addpar
With this parameter. an additional list of 2-dimensional, non-flux parameters can be retrieved. Use the format
param1/param2/.../paramxto list the parameters. Please be consistent in using either the parameter IDs or the short names as defined by MARS.- doubleelda
Use this to double the ensemble member number by adding further disturbance to each member (to be used with 25 members).
- debug
If set to
1, all temporary files are preserved. Otherwise, everything except the final output files will be deleted.- request
This produces an extra csv file
mars_requests.csvwhere the content of each MARS request submitted within the job is stored, which is useful for debugging and documentation. Possible values are 0 for normal data retrieval, 1 for not retrieving data and just writing out the MARS requests, and 2 to retrieve data and write out requests.- mailfail
As a default, e-mails are sent to the mail address defined for the ECMWF user account. It is possible to overwrite this by specifying one or more e-mail addresses (comma-separated list). In order to include the e-mail associated with the user account, add
${USER}to the list.
Hints for proper definition of certain parameter combinations¶
- Field type and time
This combination is very important. It defines the temporal resolution and which field type is extracted on each time step. The time declaration for analysis (AN) fields uses the times of the specific analysis while the (forecast time) step has to be
0. The forecast field types (e.g. FC, CF, CV, PF) need to declare a combination of (forescast start) time and the (forecast) step. Together they define the actual time. It is important to know the forecast starting times for the dataset to be retrieved, since they are different. In general, it is sufficient to give information for the exact time steps, but it is also possible to have more time step combinations ofTYPE,TIMEandSTEPbecause the temporal (hourly) resolution with theDTIMEparameter will select the correct combinations.Example of a setting for the field types and temporal resolution. It will retrieve 3-hourly fields, with analyses at 00 and 12 UTC and the corresponding forecasts inbetween.¶DTIME 3 TYPE AN FC FC FC AN FC FC FC TIME 00 00 00 00 12 12 12 12 STEP 00 03 06 09 00 03 06 09
- Vertical velocity
The vertical velocity for
FLEXPARTis not directly available from MARS and has to be calculated. There are several options for this, and the following parameters are responsible for the selection. See Vertical wind for a detailed explanation. UsingETADIFF 1,OMEGA 1andOMEGADIFF 1is recommended for debugging and testing only. Usually, one has to decide betweenGAUSS 1andETA 1.GAUSS 1means that spectral fields of the horizontal wind fields and the divergence are retrieved and that the vertical velocity is calculate using the continuity equation.ETA 1means that horizontal wind fields etadot are retrieved on a regular lat-lon grid. It is recommended to useETA 1where possible, as there is a substantial computational overhead for solving the continuity equation.Example setting for the vertical coordinate retrieval (recommended if etadot fields are available).¶GAUSS 0 ETA 1 ETADIFF 0 DPDETA 1 OMEGA 0 OMEGADIFF 0
- Grid resolution and domain
The grid and domain parameters depends on each other.
gridrefers to the grid resolution. It can be given as decimal values (e.g.,1.meaning 1.0°), or as in previous versions of flex_extract, as integer values refering to 1/1000 degrees (e.g.,1000means also 1°). The code applies common sense to determine what format is to be assumed. After selecting grid, thedomainhas to be defined. The extension in longitude or latitude direction must be an integer multiple ofgrid.The horizontal resolution for spectral fields is set by the parameter
RESOL. For information about how to select an appropriate value please read the explanation of the MARS keyword RESOL as found in this entry of the ECMWF on-line documentation and this table (also ECMWF documentation).Example setting for a domain covering the northern hemisphere domain with a grid resolution of0.25°.¶GRID 0.25 RESOL 799 SMOOTH 0 UPPER 90. LOWER 0. LEFT -179.75 RIGHT 180.
- Flux data
Flux fields are always forecast fields and contain values of the fluxes accumulated since the start of the respective forecast. As certain re-analysis dataset cover all time steps with analysis fields, it was necessary to define a new parameter set for the definition of the flux fields. The following parameters are used specifically for flux fields.
ACCTYPEis the field type (must be a type of forecast),ACCTIMEthe forecast starting time, andACCMAXSTEPthe maximum forecast step;``DTIME`` the temporal resolution. ACCTYPE is assumed to be the same during the whole period given by ACCTIME and ACCMAXSTEP. These values will be set automatically if not provided in aCONTROLfile.Example setting for the definition of flux fields.¶DTIME 3 ACCTYPE FC ACCTIME 00/12 ACCMAXSTEP 36