Disaggregation of flux data¶
FLEXPART interpolates meteorological input data linearly to the position of computational
particles in time and space. This method requires point values in the discrete input fields.
However, flux data (as listed in table Flux fields below) from the ECMWF represent cell
averages or integrals and are accumulated over a specific time interval, depending on the data
set. Hence, to conserve the integral quantity with the linear interpolation used in FLEXPART,
pre-processing has to be applied.
Short Name |
Name |
Units |
Disaggregation |
|---|---|---|---|
LSP |
large-scale precipitation |
m |
precipitation |
CP |
convective precipitation |
m |
precipitation |
SSHF |
surface sensible heat flux |
J m \(^{-2}\) |
flux |
EWSS |
eastward turbulent surface stress |
N m \(^{-2}\) s |
flux |
NSSS |
northward turbulent surface stress |
N m \(^{-2}\) s |
flux |
SSR |
surface net solar radiation |
J m \(^{-2}\) |
flux |
The first step is to de-accumulate the fields in time so that each value represents non-overlapping integrals in x-, y-, and t-space.
Afterwards, a disaggregation scheme is applied which means to convert the integral value to corresponding point values to be used late for the interpolation.
The disaggregation procedure as proposed by Paul James (currently, the standard) requires additional flux data for one day at the beginning and one day at the end of the period specified.
They are retrieved automatically. Thus, data for flux computation will be requested for the period START_DATE-1 to END_DATE+1. Note that these (additional) dates are used only for interpolation within flex_extract and are not contained in the final FLEXPART input files.
The flux disaggregation produces files named fluxYYYYMMDDHH, where YYYYMMDDHH is the date format. Note that the first two and last two flux files do not contain any data.
Note
Note also that for operational retrievals (BASETIME set to 00 or 12), forecast fluxes are only available until BASETIME, so that no polynomial interpolation is possible in the last two time intervals. This is the reason why setting BASETIME is not recommended for on-demand scripts.
Disaggregation for precipitation in older versions¶
In flex_extract up to version 5, the disaggregation was done with a Fortran program (FLXACC2). In version 6, this part was recoded in Python.
In the old versions (below 7.1), a relatively simple method processes the precipitation fields in a way that is consistent with the linear interpolation between times where input fields are available that is applied in FLEXPART for all variables.
This scheme (from Paul James) at first divides the accumulated values by the number of hours (i.e., 3 or 6).
The best option for disaggregation, which was realised, is conservation within the interval under consideration plus the two adjacent ones.
Unfortunately, this leads to undesired temporal smoothing of the precipitation time series – maxima are damped and minima are raised.
It is even possible to produce non-zero precipitation in dry intervals bordering a precipitation period as shown in Fig. 1.
This is obviously undesirable as it will affect wet scavenging, a very efficient removal process for many atmospheric trace species.
Wet deposition may be produced in grid cells where none should occur, or too little may be produced in others. This could lead to an unrealistic, checkerboard-like deposition fields.
Horizontally, the precipitation values are averages for a grid cell around the grid point to which they are ascribed, and FLEXPART uses bilinear interpolation to obtain precipitation rates at particle positions.
However, the supporting points in space are not shifted between precipitation and other variables as is the case for the temporal dimension.
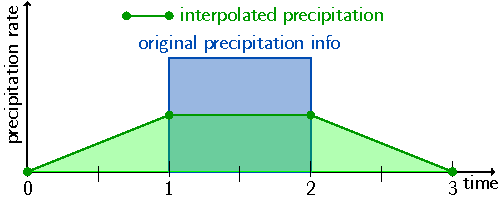
Fig. 1: Example of disaggregation scheme as implemented in older versions for an isolated precipitation event lasting one time interval (thick blue line). The amount of original precipitation after de-accumulation is given by the blue-shaded area. The green circles represent the discrete grid points after disaggregation and linearly interpolate in between them as indicated by the green line and the green-shaded area. Note that supporting points for the interpolation are shifted by half a time interval compared to the times when other meteorological fields are available (Hittmeir et al. 2018).¶
Disaggregation is done for four adjacent time intervals (\(a_0, a_1, a_2, a_3\)) which generates a new, disaggregated value which is output at the central point of the four adjacent time intervals.
This new point \(p\) is used for linear interpolation of the complete timeseries afterwards. If one of the four original time intervals has a value below 0, it is set to 0 prior to the calculation.
Disaggregation for precipitation in version 7.1¶
Due to the problems mentioned above, a new algorithm was developed. The approach is based on a one-dimensional, piecewise-linear function with two additional supporting grid points within each grid cell, dividing the interval into three pieces. It fulfils the desired requirements of preserving the integral precipitation in each time interval, guaranteeing continuity at interval boundaries, and maintaining non-negativity. An additional filter improves monotonicity. The more natural requirements of symmetry, reality, computational efficiency and easy implementation motivates the use of a linear formulation. These requirements for the reconstruction algorithm imply that time intervals with no precipitation remain unchanged, i. e., the reconstructed values vanish throughout this whole time interval, too. In the simplest scenario of an isolated precipitation event, where in the time interval before and after the data values are zero, the reconstruction algorithm therefore has to vanish at the boundaries of the interval, too. The additional conditions of continuity and conservation of the precipitation amount then require us to introduce sub-grid points if we want to keep a linear interpolation (Fig. 2). The height is thereby determined by the condition of conservation of the integral of the function over the time interval.
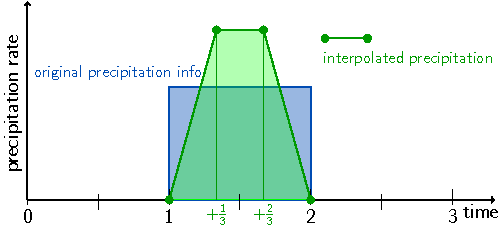
Fig. 2: Precipitation rate linearly interpolated using a sub-grid with two additional points. Colours as in Fig. 1 (Hittmeir et al. 2018).¶
Figure 3 shows an overview of the new algorithm and its components.
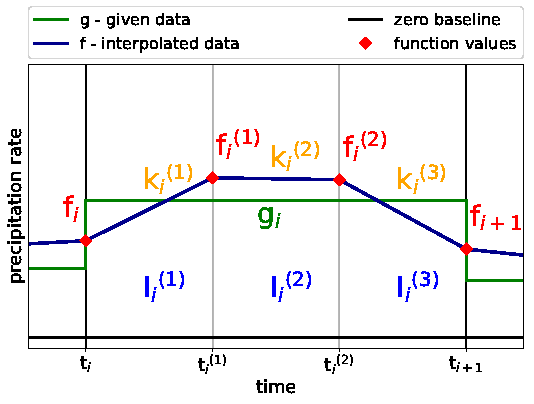
Fig. 3: Schematic overview of the basic notation in a precipitation interval with the original precipitation rate g (green) as a step function and the interpolated data \(f\) (dark blue) as the piecewise linear function. The original time interval with fixed grid length \(\delta t\) is split equidistantly in three subintervals denoted by \(I_i^{1,2,3}\), with the slopes in the subintervals as denoted by \(k_i^{1,2,3}\) . The sub-grid function values \(f_i, f_i^{1,2}, f_{i+1}\) are marked by red diamonds (Hittmeir et al. 2018).¶
The following lists the equations of the new algorithm.
In the case of the new disaggregation method for precipitation, the two new sub-grid points are added in the flux output files. They are identified by the forecast step parameter step which is 0 for the original time interval, and 1 or 2, respectively, for the two new sub-grid points. The filenames do not change.
Note
The new method for disaggregation was published in the journal Geoscientific Model Development in 2018:
Hittmeir, S., Philipp, A., and Seibert, P.: A conservative reconstruction scheme for the interpolation of extensive quantities in the Lagrangian particle dispersion model FLEXPART, Geosci. Model Dev., 11, 2503-2523, https://doi.org/10.5194/gmd-11-2503-2018, 2018.
Disaggregation for the other flux fields¶
The accumulated values for the other variables are first divided by the number of hours and then disaggregates to the exact times and conserves the integrals of the fluxes within each timespan. Disaggregation is done for four adjacent time intervals (\(F_0, F_1, F_2, F_3\)) which produces a new, disaggregated value that is the output at the central point of the four adjacent time intervals. This new point \(F\) is used for linear interpolation of the complete timeseries afterwards.